CS/NLP
[NLP] Auto Encoder (1)
sliver__
2022. 8. 11. 00:40
728x90
[오토인코더 & GAN]
- 지도 없이도 latent representation 또는 coding, 입력 데이터의 밀집을 표현하는 인공 신경망
- 입력보다 훨씬 낮은 차원을 가지므로 차원 축소 및 시각화에 유용하다.
- Generative model은 훈련 데이터와 매우 비슷한 새로운 데이터를 생성한다.
- GAN은 이미지 편집, 초해상도, 데이터 증식 등에 사용된다.
- 오토인코더는 데이터를 효율적으로 표현하는 방법을 배우게 한다.
- GAN은 생성자/판별자로 구성된다.
- Adversarial traning
[인코더 & 디코더]
- 인코더 ( Encoder )
- 입력을 내부 표현으로 바꾼다
- 디코더 ( Decoder )
- 내부 표현을 출력으로 바꾸는 디코더 ( 또는 generative model )

- 오토인코더가 입력을 재구성하기 때문에 출력을 reconstruction이라고 부른다.
- cost function은 construction이 input과 다를 때 벌점을 부과하는 reconstruction loss를 포함한다.
- undercomplete는 내표의 표현이 입력 데이터보다 저차원이다.
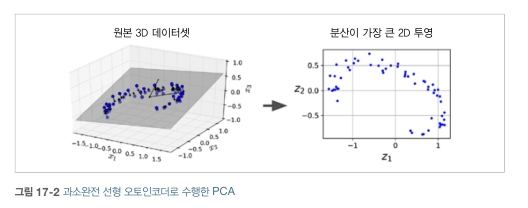
[과소완전 선형 오토인코더로 PCA 수행]
- 단순한 PCA를 수행하기 위해서는 활성화 함수를 사용하지 않으며 비용 함수는 MSE이다.
- 동일한 데이터 셋이 입력과 타깃이다.
- 오토인코더는 데이터에 분산이 가능한 많이 보존되도록 데이터를 투영할 최상의 2D 평면을 찾는다 ( 입력 : 3D )
[적층 오토인코더]
- 오토인코더도 은닉층을 여러 개 가질 수 있다.
- stacked autoencoder 또는 deep autoencoder 라고 한다.
- 오토인코더가 너무 강력해진다면 각각의 입력 데이터를 임의의 한 숫자로 매핑하도록 학습하고 디코더는 임의의 숫자로 매핑을 학습하게 된다.
- 이럴 경우 reconstruction은 완벽하지만 유용한 데이터 표현을 학습하지 못할 것이다.
- stacked autoencoder의 기준은 코딩 층을 기준으로 대칭이다.
[가중치 묶기]
- 오토인코더가 대칭일 땐 디코더의 가중치와 인코더의 가중치를 묶는게 일반적인 방법이다.
- 모델에 있는 가중치의 수를 절반으로 줄여서 훈련 속도를 높이고 과대적합의 위험을 줄여준다.
- N개의 층을 갖고 $W_{L}$이 L번째 층의 가중치를 나타낸다고 했을 때 (첫 번째 은닉층, N/2는 코딩 층, N은 출력층) 디코더 층의 가중치는 $ W_{N-L+1} = W_{L}^{T} $ 이다.
[한 번에 오토인코더 한 개씩 훈련하기]
- 한 번에 전체 오토인코더를 훈련하는 것보다 오토인코더 하나를 훈련하고 이를 쌓아올려서 한 개의 적층 오토인코더를 만들 수 있다.
- 많은 오토 인코더를 훈련해 아주 깊은 적층 오토인코더를 만들 수 있다.

[합성곱 오토인코더]
- convolution autoencoder : 이미지에 대한 오토인코더
- 합성곱층과 풀링 층으로 구성된 일반적인 CNN
- 인코더 : 공간 방향의 차원을 줄이고 channel을 늘린다.
- 디코더 : 이미지 스케일을 늘리고 channel을 원본 차원으로 돌린다.
[순환 오토인코더]
- 시계열이나 텍스트와 같은 시퀀스에 대한 오토인코더를 recurrent autoencoder로 만들 수 있다.
- 인코더 : 입력 시퀀스를 하나의 벡터로 합축하는 시퀀스-투-벡터 RNN
- 디코더 : 벡터 - 투 - 시퀀스 RNN
728x90